본 내용은 [멀티캠퍼스] 데이터 분석&데이터 엔지니어링 취업캠프 28회차에서 실시한 수업 내용 중 일부입니다.
교재 홍보 (본 과정의 SQL 교재)
교재 구매: https://www.yes24.com/Product/Goods/86544423
SQL로 맛보는 데이터 전처리 분석 - 예스24
SQL을 이용하여 현업에서 자주 사용되는 KPI 지표를 직접 추출해본다데이터 분석을 하기 위해서는 데이터베이스에 존재하는 데이터를 직접 추출할 수 있어야 한다. SQL은 우리가 데이터베이스에
www.yes24.com

3장
3장에서 다루는 내용는 SELECT외의 INSERT, DELETE, UPDATE이다.
INSERT, SELECT, UPDATE, DELETE 이 4가지를 합쳐서 CRUD라고 한다.
CRUD란?
데이터베이스에서 데이터를 다루는 기본적인 작업을 나타내는 약어이다.
CRUD 작업은 데이터베이스 애플리케이션 및 웹 애플리케이션에서 매우 중요하다. 이러한 작업을 사용하여 데이터를 생성, 읽기, 업데이트 및 삭제하면 애플리케이션은 사용자에게 데이터를 효과적으로 제공하고 관리할 수 있다. 데이터베이스 시스템의 다양한 기능과 함께 CRUD 작업을 수행하여 데이터를 관리하고 조작할 수 있다.
CRUD 종류:
1. Create (C): 데이터베이스에 새로운 데이터를 생성하거나 추가한다. 이 작업은 INSERT 문을 사용하여 수행된다. 새로운 레코드를 데이터베이스 테이블에 삽입하는 데 사용된다.
추가로, 이는 SQL CREATE문과도 관련이 있다. 데이터를 삽입하고 새로운 레코드를 생성하는 것이 주요 목적이다.
2. Read (R): 데이터베이스에서 데이터를 읽거나 조회한다. 이 작업은 SELECT 문을 사용하여 수행된다. 데이터를 검색하고 읽어오는 데 사용된다.
3. Update (U): 데이터베이스에 이미 저장된 데이터를 업데이트하거나 수정한다. 이 작업은 UPDATE 문을 사용하여 수행된다. 기존 데이터를 변경하거나 수정하는 데 사용된다.
4. Delete (D): 데이터베이스에서 데이터를 삭제한다. 이 작업은 DELETE 문을 사용하여 수행된다. 데이터를 영구적으로 제거하는 데 사용된다.
INSERT와 CREATE의 차이점:
- INSERT: 새로운 데이터를 데이터베이스 테이블에 삽입하는 데 사용된다. 이 명령문은 데이터베이스 테이블의 새로운 레코드를 생성하고 데이터를 추가한다. 따라서 INSERT 문은 CRUD의 "Create" 작업에 해당한다.
- CREATE: 데이터베이스 객체를 생성하는 데 사용된다. 주로 CREATE TABLE 문을 통해 새로운 테이블을 만들거나 CREATE DATABASE 문을 통해 새로운 데이터베이스를 만들 때 사용된다. CREATE 문은 데이터베이스 구조 자체를 생성하므로 CRUD의 "Create" 작업에 해당한다.
즉, INSERT 및 CREATE 문 모두 CRUD의 "Create" 작업에 해당하지만, 서로 다른 용도와 의미를 가진다. INSERT는 데이터 레코드를 생성하고 추가하는 데 사용되며, CREATE는 데이터베이스 객체(테이블, 뷰, 데이터베이스 등)를 생성하는 데 사용된다.
해당 장에서는 mulcamp이라는 새로운 DB를 생성하여 실습한다.
USE mulcamp;
1) CREATE: 데이터베이스 객체 생성
CREATE 데이터베이스객체 객체명 (
컬럼명1 데이터타입 제한조건
컬럼명2 데이터타입 제한조건
...
);- CREATE 문에서 컬럼명만 지정하고 데이터 타입을 명시하지 않으면, 대부분의 DBMS는 기본 데이터 타입을 사용다. 기본 데이터 타입은 DBMS에 따라 다를 수 있으며, MySQL에서는 컬럼명만 지정하면 VARCHAR 데이터 타입을 기본으로 사용한다.
- 제한조건은 필수적인 것은 아니다.
- 일반적으로 테이블을 생성할 때는 기본키를 지정하는 것이 좋다.
tasks라는 이름을 가진 테이블 생성
CREATE TABLE IF NOT EXISTS tasks (
task_id INT AUTO_INCREMENT
, title VARCHAR(255) NOT NULL
, start_date DATE
, due_date DATE
, priority TINYINT NOT NULL DEFAULT 3
, DESCRIPTION TEXT
, PRIMARY KEY (task_id)
)
;
SELECT * FROM tasks;
- CREATE TABLE IF NOT EXISTS tasks (...): 이 부분은 "tasks"라는 이름의 테이블을 생성하려는 것을 나타낸다. IF NOT EXISTS 구문은 테이블이 이미 존재하는 경우에는 새로 생성하지 않도록 한다. 즉, 테이블이 이미 존재하면 무시하고, 없을 경우에만 생성한다.
- task_id INT AUTO_INCREMENT: "task_id"라는 이름의 열을 생성하며, 이 열은 정수형(INT) 데이터 타입을 가지고 있다. AUTO_INCREMENT는 MySQL에서 사용되는 옵션으로, 이 열은 자동으로 증가되는 기본키 역할을 다. 각 행은 고유한 task_id 값을 가지게 된다.
- title VARCHAR(255) NOT NULL: "title"이라는 이름의 열을 생성하며, 이 열은 최대 255자까지 허용되는 문자열(VARCHAR) 데이터 타입을 가진다. NOT NULL 제약 조건은 이 열에는 NULL 값이 허용되지 않음을 나타냅니다. 즉, 모든 행은 "title" 값을 가져야 한다.
- start_date DATE와 due_date DATE: "start_date"와 "due_date"라는 이름의 열을 생성하며, 각각 날짜(DATE) 데이터 타입을 가진다. 이 열들은 작업의 시작 날짜와 마감 날짜를 저장하기 위한 것이다.
- priority TINYINT NOT NULL DEFAULT 3: "priority"라는 이름의 열을 생성하며, TINYINT 데이터 타입을 가진다. 이 열은 작업의 중요도를 나타내며, 기본적으로 3으로 설정된다. 이 열에도 NOT NULL 제약 조건이 적용되어 NULL 값이 허용되지 않는다.
- DESCRIPTION TEXT: "DESCRIPTION"이라는 이름의 열을 생성하며, TEXT 데이터 타입을 가진다. 이 열은 작업에 대한 자세한 설명을 저장하기 위한 것이다.
- PRIMARY KEY (task_id): "task_id" 열을 기본 키(Primary Key)로 설정한다. 기본 키는 각 행을 고유하게 식별하는 역할을 한다.
2) INSERT: 행 추가
기본키로 설정된 컬럼, NOT NULL인 컬럼은 무조건 포함해야 한다.
-- 1행 추가
INSERT INTO 테이블명(컬럼1, 컬럼2, ...)
VALUES (값1, 값2, ...)
;
-- 여러행 추가
INSERT INTO 테이블명(컬럼1, 컬럼2, ...)
VALUES
(값1, 값2, ...)
, (값3, 닶4, ...)
, (값5, 값6, ...)
...
;
title이 'Learn SQL'이고 priority가 1인 행을 추가
INSERT INTO tasks(title, priority)
VALUES ('Learn MySQL', 1);
SELECT * FROM tasks;
해당 테이블에서 기본키는 task_id로 원래라면 필수로 포함해서 쿼리를 작성해야 하지만, AUTO_INCREMENT조건으로 인해 따로 포함하지 않아도 자동으로 데이터가 추가된다.
다중행 추가
INSERT INTO tasks(title, priority)
VALUES
('Learn AWS', DEFAULT)
, ('Learn Python', 2)
, ('Learn R', 4)
, ('블로그 작성하기', 0)
;
SELECT * FROM tasks;
('Learn AWS', DEFAULT): 첫 번째 레코드를 삽입하는 부분입니다. "title" 열에는 'Learn AWS'라는 문자열 값을, "priority" 열에는 DEFAULT 키워드를 사용하여 기본값을 설정했다. "priority" 열은 기본값이 3으로 설정되어 있으므로 DEFAULT를 사용하면 3이 된다.
3) SELECT: 행 조회
해당 교재 2장에서 기본적인 설명을 했다. 자세한 내용은 아래 링크 참고
https://hsyhrae.tistory.com/32
[MySQL] SQL로 맛보는 데이터 전처리 분석(2-1)
본 내용은 [멀티캠퍼스] 데이터 분석&데이터 엔지니어링 취업캠프 28회차에서 실시한 수업 내용 중 일부입니다. 교재 홍보 (본 과정의 SQL 교재) 교재 구매: https://www.yes24.com/Product/Goods/86544423 SQL로
hsyhrae.tistory.com
https://hsyhrae.tistory.com/33
[MySQL] SQL로 맛보는 데이터 전처리 분석(2-2)
본 내용은 [멀티캠퍼스] 데이터 분석&데이터 엔지니어링 취업캠프 28회차에서 실시한 수업 내용 중 일부입니다. 교재 홍보 (본 과정의 SQL 교재) 교재 구매: https://www.yes24.com/Product/Goods/86544423 SQL로
hsyhrae.tistory.com
4) UPDATE: 행 업데이트/수정
UPDATE
테이블명
SET 컬럼명1 = 값1
, 컬럼명2 = 값2
...
WHERE 조건;- UPDATE: 업데이트 작업을 시작하는 키워드이다.
- 테이블명: 업데이트할 테이블의 이름을 지정한다.
- SET: 업데이트할 열(컬럼)과 해당 값을 설정하는 키워드이다.
- 컬럼명1 = 값1, 컬럼명2 = 값2 ...: SET 구문에서 업데이트할 열과 값을 지정한다. 각 열에 대한 업데이트할 값은 '컬럼명= 새로운 값' 형식으로 지정하며, 여러 개의 열을 한 번에 업데이트할 수 있다.
- WHERE 조건: 업데이트할 행(레코드)을 선택하는 조건을 지정합니다. 이 부분은 선택 사항이며, 지정하지 않으면 모든 행이 업데이트된다. WHERE 절을 사용하여 특정 조건을 만족하는 행만 업데이트할 수 있다.
task_id가 5인 행의 priority를 10으로 변경
UPDATE tasks
SET priority = 10
WHERE task_id = 5;
SELECT * FROM tasks;
5) DELETE: 행 삭제
DELETE FROM 테이블명
WHERE 조건;- DELETE FROM: 삭제 작업을 시작하는 키워드이다.
- table_name: 행(레코드)을 삭제할 테이블의 이름을 지정한다.
- WHERE condition: 삭제할 행(레코드)을 선택하는 조건을 지정한다. 이 부분은 선택 사항이며, 지정하지 않으면 테이블의 모든 레코드가 삭제된다. WHERE 절을 사용하여 특정 조건을 만족하는 행만 삭제할 수 있다.
task_id가 1인 행 삭제
DELETE FROM tasks
WHERE task_id = 1;
SELECT * FROM tasks;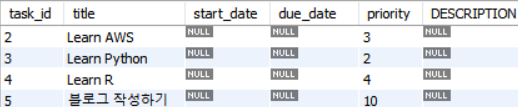
Procedure이란?
하나 이상의 SQL 문을 그룹화하여 데이터베이스에서 실행할 수 있는 저장 프로시저 또는 함수와 같은 데이터베이스 객체이다. SQL 프로시저는 주로 데이터베이스 내에서 반복적으로 수행되어야 하는 작업을 단순화하고 효율적으로 수행하기 위해 사용된다. SQL 프로시저는 일련의 SQL 문을 포함하며, 이러한 문은 트랜잭션을 관리하거나 데이터베이스에서 작업을 수행하는 데 사용된다.
일종의 사용자 정의 함수라고 볼 수 있다. PL/SQL 개념을 알고 있어야 한다. 근데 데이터 분석가에게는 필수적인 것은 아니므로 깊게 알아보진 않을 것이다.
- Procedure
DELIMITER $$
CREATE PROCEDURE 프로시저명()
BEGIN
쿼리문
END $$
DELIMITER ;
예제
DELIMITER $$
CREATE PROCEDURE mulcamp.GetTasks()
BEGIN
SELECT *
FROM tasks
ORDER BY task_id;
END $$
DELIMITER ;
CALL mulcamp.GetTasks();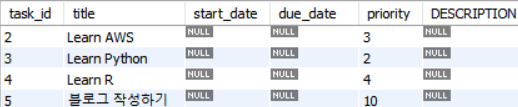
- DELIMITER $$: 이 명령은 SQL 문의 구분자(delimiter)를 변경한다. 기존의 구분자인 세미콜론(;) 대신 $$를 사용하도록 설정한다. 이는 SQL 프로시저나 트리거 등 여러 SQL 문을 하나의 논리적인 블록으로 묶을 때 필요한 설정이다.
- CREATE PROCEDURE mulcamp.GetTasks(): 이 부분은 "mulcamp" 데이터베이스 내에 "GetTasks"라는 이름의 SQL 프로시저를 생성하는 부분이다. 프로시저 내용은 BEGIN과 END 사이에 위치하게 된다.
- BEGIN: 프로시저의 시작을 나타내는 키워드이다.
- SELECT * FROM tasks ORDER BY task_id;: 이 부분은 실제로 프로시저가 수행할 작업을 정의한 SQL 문이다. "tasks" 테이블의 모든 열을 선택하고 "task_id" 열을 기준으로 정렬한다.
- END: 프로시저의 끝을 나타내는 키워드이다.
- ELIMITER ;: 구분자를 다시 기본값인 세미콜론(;)으로 변경한다.
- CALL mulcamp.GetTasks();: 생성한 "GetTasks" 프로시저를 호출하는 명령이다. 이를 실행하면 프로시저가 실행되어 "tasks" 테이블의 데이터를 가져온다.
VIEW란?
하나 이상의 테이블로부터 데이터를 검색하는데 사용되는 가상 테이블입니다. 뷰는 실제 데이터를 포함하지 않고 데이터베이스의 다른 테이블에서 가져온 결과 집합을 나타내며, 이를 통해 복잡한 쿼리를 단순화하고 데이터를 더 효과적으로 관리할 수 있습니다.
View의 주요 특징:
- 가상 테이블: 뷰는 실제 데이터를 저장하지 않고 데이터베이스 내의 다른 테이블에서 필요한 정보를 가져와 가상의 테이블로 나타낸다.
- 단순화된 쿼리: 복잡한 쿼리를 단순화하고 가독성을 높일 수 있다. 뷰를 사용하여 데이터베이스에서 필요한 부분만 선택적으로 가져올 수 있다.
- 데이터 보안: 뷰를 통해 특정 사용자에게만 필요한 데이터를 노출하고, 민감한 정보를 보호할 수 있다. 사용 권한을 통제할 수 있다.
- 재사용성: 동일한 쿼리 논리를 여러 곳에서 사용할 수 있도록 재사용성을 제공한다. 쿼리 로직을 한 곳에서 관리하면 변경이 필요한 경우 편리하다.
- 성능 향상: 뷰는 데이터를 미리 계산하지 않고 필요할 때만 데이터를 가져오므로 데이터 변경 시 자동으로 최신 정보를 제공한다. 성능 최적화에도 도움이 될 수 있다.
CREATE VIEW 뷰명
AS
쿼리
;
예제
CREATE VIEW tasksView
AS
SELECT *
FROM tasks
WHERE task_id = 4;
SELECT * FROM tasksView;
'SQL' 카테고리의 다른 글
| [MySQL] SQL로 맛보는 데이터 전처리 분석(4-2) (0) | 2023.10.10 |
|---|---|
| [MySQL] SQL로 맛보는 데이터 전처리 분석(4-1) (0) | 2023.10.10 |
| [MySQL] SQL로 맛보는 데이터 전처리 분석(2-2) (2) | 2023.10.08 |
| [MySQL] SQL로 맛보는 데이터 전처리 분석(2-1) (0) | 2023.10.07 |
| [MySQL] 셀프조인(Feat: 재구매율) (2) | 2023.10.05 |



