본 내용은 [멀티캠퍼스] 데이터 분석&데이터 엔지니어링 취업캠프 28회차에서 실시한 수업 내용 중 일부입니다.
교재 홍보 (본 과정의 SQL 교재)
교재 구매: https://www.yes24.com/Product/Goods/86544423
SQL로 맛보는 데이터 전처리 분석 - 예스24
SQL을 이용하여 현업에서 자주 사용되는 KPI 지표를 직접 추출해본다데이터 분석을 하기 위해서는 데이터베이스에 존재하는 데이터를 직접 추출할 수 있어야 한다. SQL은 우리가 데이터베이스에
www.yes24.com

ERD

실습에 앞서 우리가 다룰 데이터의 ERD를 먼저 숙지하자.
해당 포스팅에서 소개할 내용은 JOIN, CASE WHEN, 윈도우 수위 함수(RANK, DENSE_RANK, ROW_NUMBER), SUBQUERY이다.
JOIN이란?
두 개 이상의 테이블에서 데이터를 결합하여 하나의 결과 집합을 생성하는 데 사용되는 기능이다. JOIN을 사용하면 데이터베이스에서 여러 테이블 간의 관계를 활용하여 연관된 데이터를 하나의 결과로 가져올 수 있다.
JOIN의 주요 목적
1. 데이터 결합: JOIN을 사용하여 서로 다른 테이블에서 데이터를 결합할 수 있다.
2. 관계 활용: 데이터베이스 테이블 간의 관계를 활용하여 데이터를 효율적으로 가져올 수 있다.
3. 복잡한 질의 작성: JOIN을 사용하면 데이터베이스에서 복잡한 질의를 작성할 수 있다. 여러 테이블을 연결하고 필요한 데이터를 선택하여 웒는 결과를 생성할 수 있ㄷ.
JOIN의 기본적인 유형

- INNER JOIN: 두 테이블 간에 공통된 값이 있는 경우에만 해당 행을 결과에 포함시킨다.(B 조회)
- LEFT JOIN 또는 LEFT OUTER JOIN: 왼쪽 테이블의 모든 행을 결과에 포함시키고, 오른쪽 테이블과 일치하는 행이 있는 경우 해당 행을 포함시킨다. 일치하지 않는 경우 NULL 값을 가진다.(A+B 조회)
- RIGHT JOIN 또는 RIGHT OUTER JOIN: 왼쪽 테이블과 오른쪽 테이블을 교환한 LEFT JOIN과 유사하게 작동한다.(B+C 조회)
- FULL JOIN 또는 FULL OUTER JOIN: 양쪽 테이블의 모든 행을 결과에 포함시킨다. 일치하지 않는 행은 NULL 값을 가진다. MySQL에서는 직접 지원하지 않는다. 유사한 결과를 얻으려면 LEFT JOIN과 RIGHT JOIN을 조합하여야 한다.(A+B+C 조회)
1) INNER JOIN:
SELCT *
FROM 테이블명1
INNER
JOIN 테이블명2
ON 테이블명1.컬럼명 = 테이블명2.컬럼명;
두 테이블 간의 공통된 행만을 반환한다. 즉, 두 테이블에서 일치하는 행만 가져온다.
SELECT *
FROM orders A
INNER
JOIN customers B
ON A.customernumber = B.customernumber
WHERE B.country = 'USA'
;

2) LEFT JOIN:
SELCT *
FROM 테이블명1
LEFT
JOIN 테이블명2
ON 테이블명1.컬럼명 = 테이블명2.컬럼명;왼쪽 테이블의 모든 행과 오른쪽 테이블과 일치하는 행을 반환한다. 일치하지 않는 경우 오른쪽 테이블의 값은 NULL로 설정다.
SELECT *
FROM orders A
LEFT
JOIN customers B
ON A.customernumber = B.customernumber
WHERE B.country = 'USA'
;

3) RIGHT JOIN: LEFT JOIN과 반대이다.
4) FULL JOIN: 앞서 언급했듯 MySQL에서는 지원하지 않는다. 대신 유사한 결과를 얻을 수 있는 쿼리를 소개한다.
양쪽 테이블의 모든 행을 반환한다. 일치하지 않는 행의 경우 NULL 값으로 채워진다.
SELECT *
FROM orders A
LEFT
JOIN customers B
ON A.customernumber = B.customernumber
UNION ALL -- UNION ALL을 사용하여 LEFT JOIN과 RIGHT JOIN을 합친다.
SELECT *
FROM orders A
RIGHT
JOIN customers B
ON A.customernumber = B.customernumber
;

CASE WHEN이란?
SQL 쿼리에서 조건에 따라 다른 값을 반환하는 데 사용되는 제어 구조이다. CASE WHEN을 사용하면 데이터베이스에서 특정 조건을 검사하고, 조건이 참이면 하나의 값을 반환하고 조건이 거짓이면 다른 값을 반환할 수 있다. 이를 통해 데이터를 조작하거나 필터링하는 데 사용할 수 있다.
CASE WHEN 기본 구문
SELECT
CASE WHEN 조건1 THEN 결과1
WHEN 조건2 THEN 결과2
ELSE 결과3
END
FROM 테이블명;
- CASE: CASE WHEN 구문의 시작을 나타낸다.
- WHEN: 각 조건을 시작하며, condition은 평가할 조건을 나타낸다.
- THEN: 조건이 참일 때 반환할 값을 지정한다.
- ELSE: 모든 조건이 거짓인 경우 반환할 기본 값을 지정한다. 이 부분은 선택 사항이며, 생략할 수 있다.
SELECT
CASE
WHEN country IN ('USA', 'Canada') then 'North America'
ELSE 'OTHERS'
END AS region
, COUNT(customernumber) n_customers
FROM
customers
GROUP BY
1
-- CASE WHEN country IN ('USA', 'Canada') then 'North America' ELSE 'OTHERS' END 와 돌일
;
MySQL에서는 GROUP BY, ORDER BY 절에 컬럼명이나 별칭 대신 숫자를 입력하여 사용할 수 있다.
이때 숫자는 SELECT절의 컬럼명 순서이다. (첫번째 컬럼은 1이다.)
RANK, DENSEE_RANK, ROW_NUMBER란?
SQL에서 사용되는 윈도우 함수 중에서 가장 일반적인 것들 중 하나이다. 이러한 함수들은 데이터를 정렬하고 순위를 부여하는 데 사용된다.
RANK:
- RANK 함수는 데이터를 정렬한 후에 각 행에 대해 순위를 매긴다.
- 만약 두 개 이상의 행이 동일한 값에 대해 동일한 순위를 가지면 그 다음 순위는 건너뛰고 다음 순위를 부여한다.
- 예를 들어, 3개의 행이 1등인 경우, 그 다음 순위는 4등이 아니라 2등이 된다.
DENSE_RANK:
- DENSE_RANK 함수는 데이터를 정렬한 후에 각 행에 대해 밀집 순위를 부여한다.
- 동일한 값에 대해 동일한 순위를 부여하며, 그 다음 순위는 건너뛰지 않는다.
- 예를 들어, 3개의 행이 1등인 경우, 그 다음 순위는 2등이 된다.
ROW_NUMBER:
- ROW_NUMBER 함수는 데이터를 정렬한 후에 각 행에 대해 고유한 순서 번호를 부여한다.
- 동일한 값에 대해 동일한 순서 번호를 부여하지 않다. 모든 행에 대해 고유한 번호를 제공한다.
1) 순위함수:
SELECT
순위함수() OVER (ORDER BY 컬럼명)
FROM 테이블명;SELECT
buyprice
, ROW_NUMBER() OVER(ORDER BY buyprice) ROWNUMBER
, RANK() OVER(ORDER BY buyprice) RNK
, DENSE_RANK() OVER(ORDER BY buyprice) DENSERANK
FROM products
;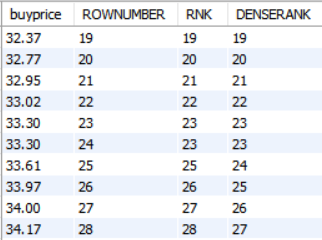
함수별로 결과가 다르게 나오는 것을 확인할 수 있다.
2) PATITION BY:
SELECT
순위함수() OVER (PARTITION BY 컬럼명1 ORDER BY 컬럼명2)
FROM 테이블명;
SQL에서 사용되는 윈도우 함수와 함께 쓰이는 절이다. 이 절은 데이터를 파티션 또는 그룹으로 나누어 분석할 때 사용된다. 각 파티션은 데이터를 분할하고 독립적으로 처리할 수 있도록 도와준다.
productline별로 나누어서 순위를 집계한다.
SELECT
productline
, buyprice
, ROW_NUMBER() OVER(PARTITION BY productline ORDER BY buyprice) ROWNUMBER
, RANK() OVER(PARTITION BY productline ORDER BY buyprice) RNK
, DENSE_RANK() OVER(PARTITION BY productline ORDER BY buyprice) DENSERANK
FROM products
;
SUBQUERY란?
SQL 쿼리 안에 포함된 다른 SQL 쿼리이다. 즉, 서브쿼리는 주 쿼리(외부 쿼리) 내부에 또 다른 쿼리(서브쿼리 또는 내부 쿼리)를 포함하는 것을 의미한다. 서브쿼리는 주로 주 쿼리의 조건에 따라 데이터를 필터링하거나 서브쿼리의 결과를 기반으로 주 쿼리에서 작업을 수행하는 데 사용된다.
사용 목적:
1. 데이터 필터링: 서브쿼리를 사용하여 주 쿼리의 결과를 제한하거나 필터링할 수 있다. 예를 들어, 특정 조건을 충족하는 행만 선택하려는 경우에 서브쿼리를 사용할 수 있다.
2. 서브쿼리 결과와 비교: 서브쿼리를 사용하여 주 쿼리의 결과와 서브쿼리의 결과를 비교하거나 서브쿼리의 결과를 기준으로 주 쿼리에서 작업을 수행할 수 있다.
3. 하위 집합 생성: 서브쿼리를 사용하여 주 쿼리의 결과 집합을 구성할 때 하위 집합을 생성할 수 있다.
서브쿼리는 다양한 형태로 사용될 수 있으며, 주로 SELECT, FROM, WHERE, HAVING, 또는 JOIN 절 내에서 사용된다.
서브쿼리는 주로 단일 값을 반환하는 경우와 다중 값을 반환하는 경우로 나눌 수 있다.
1) 단일 값 서브쿼리
SELECT
*
FROM orders
WHERE ordernumber >= (SELECT AVG(ordernumber)
FROM orders
);
서브 쿼리는 ordernumber의 평균을 반환한다.
주쿼리에서는 ordernumber가 ordernumber의 평균보다 높은 경우만 조회한다.
2) 다중 값 서브쿼리
SELECT
*
FROM orders
WHERE ordernumber IN (SELECT ordernumber
FROM orders
WHERE
comments LIKE 'Customer%'
);
서브쿼리는 comments가 Customer로 시작하는 ordernumber 반환한다.
주쿼리에서는 서브쿼리의 결과에 포함된 ordernumber를 가진 데이터만 조회한다.
3) FROM절에서 사용
SELECT
*
FROM (
SELECT
customernumber
, city
FROM customers
WHERE city = 'NYC'
) A
;FROM, JOIN절에서 사용하는 경우 항상 A와 같은 문자열을 사용해 주어야 한다.
서브쿼리는 city가 NYC인 customernumber와 city를 반환한다.
주쿼리에서는 서브쿼리의 결과에 포함된 city, customernumber를 가진 데이터만 조회한다.
'SQL' 카테고리의 다른 글
| [MySQL] SQL로 맛보는 데이터 전처리 분석(4-1) (0) | 2023.10.10 |
|---|---|
| [MySQL] SQL로 맛보는 데이터 전처리 분석(3) (0) | 2023.10.10 |
| [MySQL] SQL로 맛보는 데이터 전처리 분석(2-1) (0) | 2023.10.07 |
| [MySQL] 셀프조인(Feat: 재구매율) (2) | 2023.10.05 |
| [MySQL] 실습하기 전 데이터 다운로드 및 불러오기 (0) | 2023.10.05 |



